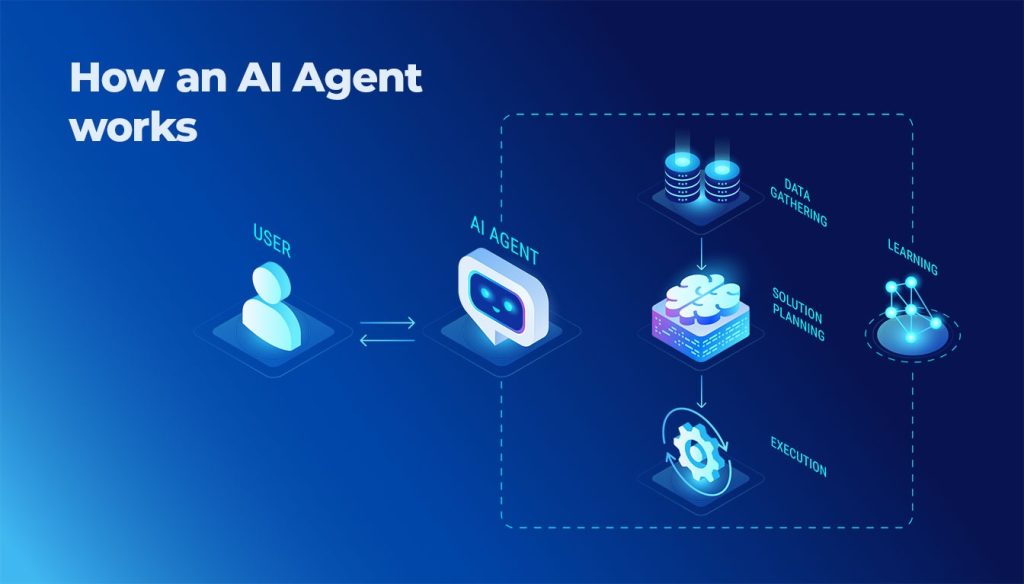
In previous blog posts, we’ve learnt about Artificial Intelligence, Computer Vision, Machine Learning and, more specifically, Deep Learning. In this article, we’re going to look at one of the main signs indicating that a project requires the use of Machine Learning.
Business logic based on excessive rules and/or conditions
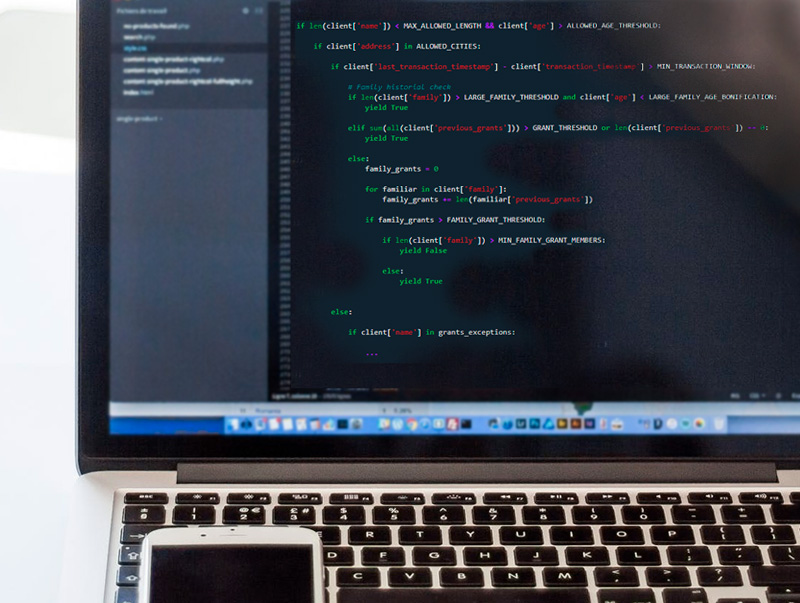
One of the main symptoms of the need for Machine Learning in a project is when the number of possibilities to be considered at the time of carrying out a task is overwhelming. Take for example the problem of determining the viability of a bank loan. An expert committee may decide that the viability of granting a loan is determined by an arbitrarily large number of indicators (annual income, geographical location, date, and so on).
Accordingly, a development team can establish rules programmatically for each of the indicators identified. For example, based on the work of the expert committee, the developers could define that annual gross income has to exceed a particular value, that the geographical location does not have to be any particular one, or even that, when both these are combined, other combinations of indicators come into play. Note that the complexity involved in defining this system is already increasing, especially when several values and therefore several thresholds exist for a single indicator. This is a common problem with any rule-based system.
In this scenario, experience tells us that, in practically all these systems, there are special cases that, sooner or later, need to be addressed by extending the rules. This means that the following must always be in place:
- A study on the impact of the indicators, requiring an expert committee to assess the impact over time.
- A translation of the rules within the computer system by a development team. This includes maintaining these rules over time.
These points can be applied to any other field or problem that relies on a rule-based system. Although sometimes the rule-based system can be maintained entirely manually, this approach usually presents a series of problems that can become significant. In addition, it’s not uncommon for these problems to develop some time after implementing the system. This manual approach:
- Makes cleaning up the rules difficult: Adding new rules or combinations of rules can be an extremely difficult task when the complexity of the system begins to increase significantly, creating more effort for the IT team implementing and/or maintaining them.
- Limits the capacity for generalisation: It is not uncommon to find that these systems are rigid when it comes to complying with the rules. For example, a slight variation in one data item is likely to invalidate the rule-based system completely where, in most cases, this is not the desired outcome.
If these points sound familiar to you, you’re probably interested to know that there is another way to define these rules that solves these problems and automates the process, a solution that involves the use of Machine Learning.
Machine Learning to infer rules based on data
The idea behind using Machine Learning instead of an engine based purely on manually defined rules is to delegate the process of inferring these rules to the machine. This process can be done by collecting all possible examples of the problem and using a Machine Learning model to adjust to them.
In the example we are using here, the data collected would be the different combinations of the values of the indicators selected and the information on whether the bank manager approved the loan or not. This is a classic supervised learning problem and, therefore, a Machine Learning model can be trained with this data to learn in which cases the result is positive (loan approved) and in which it is negative (loan refused).
When the model is trained successfully, it is not uncommon to find that it is also capable of generalising, which means that, when it encounters new cases not used to train the system, the model is able to provide an answer that has a high probability of being valid for the purpose of approving the loan. Furthermore, the probability of success in new cases can be improved by including a greater number of examples when training the model.
Consequently, a trained Machine Learning model will automatically extract the patterns that define the validity of approving a loan from the indicators provided and the training examples used. It is also possible (and not uncommon) that there are patterns so complex that they are beyond the knowledge and experience of an expert. This is the case with Google Translate, which used to be based on vocabulary, grammar and syntax rules defined manually by experts. In 2005, however, it was converted into a Statistical Machine Translation (SMT) [1] system to enable it to adapt automatically based on examples, and in 2016, it was eventually converted into a Neural Machine Translation (NMT)[2], system, which uses neural networks as part of the translation process, dramatically improving accuracy compared with the rule-based engine that had been perfected over many years.
This is the first part of a series of articles on the signs indicating the need for Machine Learning, Computer Vision and/or Deep Learning in a project. Subscribe to our newsletter so you don’t miss out on the other signs that might indicate the need for AI in a project.
Iván de Paz Centeno is a Data Scientist and R&D Engineer at Xeridia
[1] Och, F. J. (2005). Statistical machine translation: Foundations and recent advances. Tutorial at MT Summit.
[2] Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., … & Klingner, J. (2016). Googles neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144.