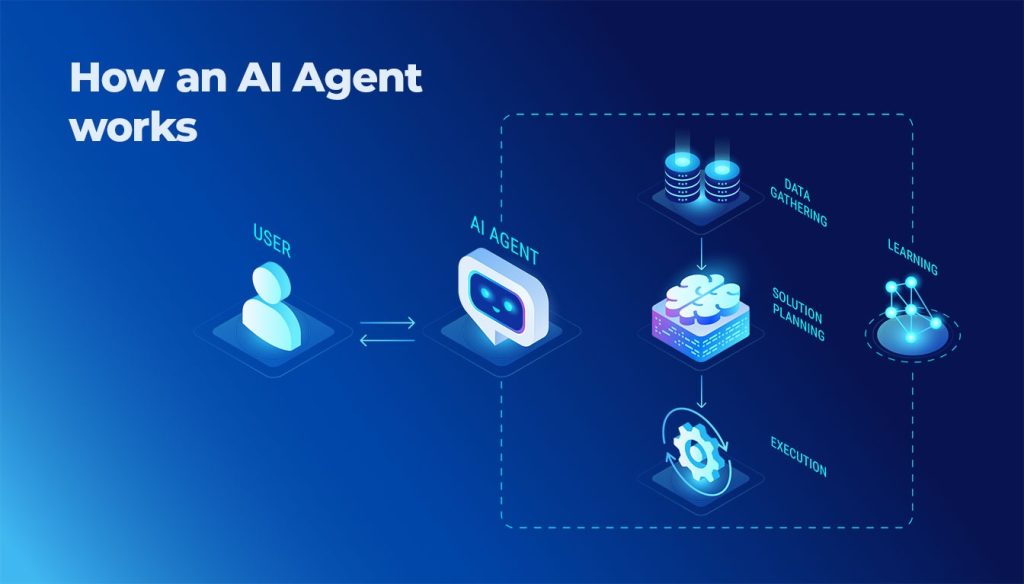

Machine Learning is a sub-branch of Artificial Intelligence that aims to solve problems without the need to explicitly program the algorithm that solves them. To do this successfully, data is needed for the system to be able to infer patterns.
The concept of Machine Learning is greatly influenced by the ability of human beings to learn. For example, if a person who has never seen a dragon fruit is told that it is a pinkish-skinned fruit and that inside it is white with black speckles, it would be very easy to detect it in a basket full of different types of fruit. Furthermore, even without us providing a description, a person who knew every fruit in the basket except the dragon fruit would be able to deduce that this unknown fruit is the one we are looking for. These types of deductions, which for human beings seem very simple, are extremely complex for computers to perform.
As we saw in the previous post on the role of Artificial Intelligence today, as early as 1950, Alan Turing proposed his famous Turing Test[1] to determine whether a machine had intelligent behaviour or not. In that same decade, Arthur Samuel created the first machine learning system,[2] designed to learn the best moves a player could make in a game of draughts based on numerous recorded games. This experiment was so successful that, once trained, the machine was able to beat its creator.
Neural networks, which everyone is talking about today and which are the basis of Deep Learning (which we will discuss in a later blog post) were also invented in the same decade. In 1951, Marvin Minsky and Dean Edmonds created SNARC, the first artificial neural network, built using 3000 vacuum valves to simulate 40 artificial neurons. However, neural networks were not widely used until the 1980s when the Backpropagation Algorithm was first implemented to train neural networks quickly and efficiently.
Thanks to the phenomenal advances in computer technology in terms of computing speed and storage, Machine Learning is in its prime today. This, combined with the availability of an ever increasing amount of data, means that the range of applications for this branch of Artificial Intelligence is increasing exponentially.
Every Machine Learning process has at least two very distinct phases: training and prediction.
” Every Machine Learning process has at least two very distinct phases: training and prediction.”
First phase of the Machine Learning process: Training
In this phase, the system tries to learn trends, behaviours and/or patterns that conform to the data contained in the training package. From a mathematical point of view, training an intelligent system corresponds to a process of optimising the parameters of a function so that its output is as close as possible to the result we want to obtain.
Depending on the data we have to train our system, there are two main categories of learning:
- If our data set has an expected result, we have a case of supervised learning. This means that the data we are using to train our intelligent system consists of a set of characteristics that define each piece of data and the result we want to obtain with the data. For example, a system that, because of the size of a house, can estimate its market price.
- By contrast, if we only have data but do not have any value that determines the objective we want to achieve with the training, we categorise this as unsupervised learning. This type of learning is used to make groupings, to look for anomalous data within a data set or even to reduce the characteristics of the data to leave us with only the most relevant. For example, a system that analyses images of people and tries to group them according to their appearance (race, age, gender, etc.).
Second phase of the Machine Learning process: Prediction
The prediction stage is performed once the training has been completed and consists of evaluating new data that was not considered for training purposes using the optimized function to obtain a result.
If the result obtained is a category, we are faced with a classification problem. For example, the result of a match in the football pools (1 x 2), the blood group to which a person belongs or whether a dog or cat appears in a photo.
If, on the other hand, the value returned by the function is a number, we are faced with a regression problem. Predicting the price of a barrel of Brent Crude or estimating a person’s weight are examples of regression.
At this point, it is very interesting for a company to be able to identify those points within a project where Machine Learning could make a difference when it comes to obtaining results. We will address this subject in future blog posts and explain how to identify this type of problem.
Oscar García-Olalla Olivera is a Data Scientist and R&D Engineer at Xeridia
[1] A. M. TURING; I.—COMPUTING MACHINERY AND INTELLIGENCE, Mind, Volume LIX, Issue 236, 1 October 1950, Pages 433–460, https://doi.org/10.1093/mind/LIX.236.433
[2] Samuel, A. L. 1959. “Some Studies in Machine Learning Using the Game of Checkers”. In Feigenbaum, E.A., Feldman, J. (eds) 1963. Computers and Thought. New York: McGraw-Hill, pp. 71-105.